
Embeddings
Embeddings models convert text into numerical vectors. These embeddings capture semantic meaning of the input text, and allow LLMs to understand context.
Refer to your specific component's documentation for more information on parameters.
Use an embeddings model component in a flow
In this example of a document ingestion pipeline, the OpenAI embeddings model is connected to a vector database. The component converts the text chunks into vectors and stores them in the vector database. The vectorized data can be used to inform AI workloads like chatbots, similarity searches, and agents.
This embeddings component uses an OpenAI API key for authentication. Refer to your specific embeddings component's documentation for more information on authentication.

AI/ML
This component generates embeddings using the AI/ML API.
Inputs
model_name
String
The name of the AI/ML embedding model to use
aiml_api_key
SecretString
API key for authenticating with the AI/ML service
Outputs
embeddings
Embeddings
An instance of AIMLEmbeddingsImpl for generating embeddings
Amazon Bedrock Embeddings
This component is used to load embedding models from Amazon Bedrock.
Inputs
credentials_profile_name
String
Name of the AWS credentials profile in ~/.aws/credentials or ~/.aws/config, which has access keys or role information
model_id
String
ID of the model to call, e.g., amazon.titan-embed-text-v1. This is equivalent to the modelId property in the list-foundation-models API
endpoint_url
String
URL to set a specific service endpoint other than the default AWS endpoint
region_name
String
AWS region to use, e.g., us-west-2. Falls back to AWS_DEFAULT_REGION environment variable or region specified in ~/.aws/config if not provided
Outputs
embeddings
Embeddings
An instance for generating embeddings using Amazon Bedrock
Astra DB vectorize
Connect this component to the Embeddings port of the Astra DB vector store component to generate embeddings.
This component requires that your Astra DB database has a collection that uses a vectorize embedding provider integration. For more information and instructions, see Embedding Generation.
Inputs
provider
Embedding Provider
The embedding provider to use
model_name
Model Name
The embedding model to use
authentication
Authentication
The name of the API key in Astra that stores your vectorize embedding provider credentials. (Not required if using an Astra-hosted embedding provider.)
provider_api_key
Provider API Key
As an alternative to authentication, directly provide your embedding provider credentials.
model_parameters
Model Parameters
Additional model parameters
Outputs
embeddings
Embeddings
An instance for generating embeddings using Astra vectorize
Azure OpenAI Embeddings
This component generates embeddings using Azure OpenAI models.
Inputs
Model
String
Name of the model to use (default: text-embedding-3-small)
Azure Endpoint
String
Your Azure endpoint, including the resource. Example: https://example-resource.azure.openai.com/
Deployment Name
String
The name of the deployment
API Version
String
The API version to use, options include various dates
API Key
String
The API key to access the Azure OpenAI service
Outputs
embeddings
Embeddings
An instance for generating embeddings using Azure OpenAI
Cloudflare Workers AI Embeddings
This component generates embeddings using Cloudflare Workers AI models.
Inputs
strip_new_lines
Strip New Lines
Whether to strip new lines from the input text
batch_size
Batch Size
Number of texts to embed in each batch
api_base_url
Cloudflare API base URL
Base URL for the Cloudflare API
headers
Headers
Additional request headers
Outputs
embeddings
Embeddings
An instance for generating embeddings using Cloudflare Workers
Cohere Embeddings
This component is used to load embedding models from Cohere.
Inputs
cohere_api_key
String
API key required to authenticate with the Cohere service
model
String
Language model used for embedding text documents and performing queries (default: embed-english-v2.0)
truncate
Boolean
Whether to truncate the input text to fit within the model's constraints (default: False)
Outputs
embeddings
Embeddings
An instance for generating embeddings using Cohere
Embedding similarity
This component computes selected forms of similarity between two embedding vectors.
Inputs
embedding_vectors
Embedding Vectors
A list containing exactly two data objects with embedding vectors to compare.
similarity_metric
Similarity Metric
Select the similarity metric to use. Options: "Cosine Similarity", "Euclidean Distance", "Manhattan Distance".
Outputs
similarity_data
Similarity Data
Data object containing the computed similarity score and additional information.
Google generative AI embeddings
This component connects to Google's generative AI embedding service using the GoogleGenerativeAIEmbeddings class from the langchain-google-genai package.
Inputs
api_key
API Key
Secret API key for accessing Google's generative AI service (required)
model_name
Model Name
Name of the embedding model to use (default: "models/text-embedding-004")
Outputs
embeddings
Embeddings
Built GoogleGenerativeAIEmbeddings object
Hugging Face Embeddings
This component loads embedding models from HuggingFace.
Use this component to generate embeddings using locally downloaded Hugging Face models. Ensure you have sufficient computational resources to run the models.
Inputs
Cache Folder
Cache Folder
Folder path to cache HuggingFace models
Encode Kwargs
Encoding Arguments
Additional arguments for the encoding process
Model Kwargs
Model Arguments
Additional arguments for the model
Model Name
Model Name
Name of the HuggingFace model to use
Multi Process
Multi-Process
Whether to use multiple processes
Outputs
embeddings
Embeddings
The generated embeddings
Hugging Face embeddings inference
This component generates embeddings using Hugging Face Inference API models and requires a Hugging Face API token to authenticate. Local inference models do not require an API key.
Use this component to create embeddings with Hugging Face's hosted models, or to connect to your own locally hosted models.
Inputs
API Key
API Key
The API key for accessing the Hugging Face Inference API.
API URL
API URL
The URL of the Hugging Face Inference API.
Model Name
Model Name
The name of the model to use for embeddings.
Cache Folder
Cache Folder
The folder path to cache Hugging Face models.
Encode Kwargs
Encoding Arguments
Additional arguments for the encoding process.
Model Kwargs
Model Arguments
Additional arguments for the model.
Multi Process
Multi-Process
Whether to use multiple processes.
Outputs
embeddings
Embeddings
The generated embeddings.
Connect the Hugging Face component to a local embeddings model
To run an embeddings inference locally, see the HuggingFace documentation.
To connect the local Hugging Face model to the Hugging Face embeddings inference component and use it in a flow, follow these steps:
Create a Vector store RAG flow. There are two embeddings models in this flow that you can replace with Hugging Face embeddings inference components.
Replace both OpenAI embeddings model components with Hugging Face model components.
Connect both Hugging Face components to the Embeddings ports of the Astra DB vector store components.
In the Hugging Face components, set the Inference Endpoint field to the URL of your local inference model. The API Key field is not required for local inference.
Run the flow. The local inference models generate embeddings for the input text.
IBM watsonx embeddings
This component generates text using IBM watsonx.ai foundation models.
To use IBM watsonx.ai embeddings components, replace an embeddings component with the IBM watsonx.ai component in a flow.
An example document processing flow looks like the following:

This flow loads a PDF file from local storage and splits the text into chunks.
The IBM watsonx embeddings component converts the text chunks into embeddings, which are then stored in a Chroma DB vector store.
The values for API endpoint, Project ID, API key, and Model Name are found in your IBM watsonx.ai deployment. For more information, see the Langchain documentation.
Default models
The component supports several default models with the following vector dimensions:
sentence-transformers/all-minilm-l12-v2: 384-dimensional embeddingsibm/slate-125m-english-rtrvr-v2: 768-dimensional embeddingsibm/slate-30m-english-rtrvr-v2: 768-dimensional embeddingsintfloat/multilingual-e5-large: 1024-dimensional embeddings
The component automatically fetches and updates the list of available models from your watsonx.ai instance when you provide your API endpoint and credentials.
Inputs
url
watsonx API Endpoint
The base URL of the API.
project_id
watsonx project id
The project ID for your watsonx.ai instance.
api_key
API Key
The API Key to use for the model.
model_name
Model Name
The name of the embedding model to use.
truncate_input_tokens
Truncate Input Tokens
The maximum number of tokens to process. Default: 200.
input_text
Include the original text in the output
Determines if the original text is included in the output. Default: True.
Outputs
embeddings
Embeddings
An instance for generating embeddings using watsonx.ai
LM Studio Embeddings
This component generates embeddings using LM Studio models.
Inputs
model
Model
The LM Studio model to use for generating embeddings
base_url
LM Studio Base URL
The base URL for the LM Studio API
api_key
LM Studio API Key
API key for authentication with LM Studio
temperature
Model Temperature
Temperature setting for the model
Outputs
embeddings
Embeddings
The generated embeddings
MistralAI
This component generates embeddings using MistralAI models.
Inputs
model
String
The MistralAI model to use (default: "mistral-embed")
mistral_api_key
SecretString
API key for authenticating with MistralAI
max_concurrent_requests
Integer
Maximum number of concurrent API requests (default: 64)
max_retries
Integer
Maximum number of retry attempts for failed requests (default: 5)
timeout
Integer
Request timeout in seconds (default: 120)
endpoint
String
Custom API endpoint URL (default: https://api.mistral.ai/v1/)
Outputs
embeddings
Embeddings
MistralAIEmbeddings instance for generating embeddings
NVIDIA
This component generates embeddings using NVIDIA models.
Inputs
model
String
The NVIDIA model to use for embeddings (e.g., nvidia/nv-embed-v1)
base_url
String
Base URL for the NVIDIA API (default: https://integrate.api.nvidia.com/v1)
nvidia_api_key
SecretString
API key for authenticating with NVIDIA's service
temperature
Float
Model temperature for embedding generation (default: 0.1)
Outputs
embeddings
Embeddings
NVIDIAEmbeddings instance for generating embeddings
Ollama embeddings
This component generates embeddings using Ollama models.
For a list of Ollama embeddings models, see the Ollama documentation.
To use this component in a flow, connect BroxiAI to your locally running Ollama server and select an embeddings model.
In the Ollama component, in the Ollama Base URL field, enter the address for your locally running Ollama server. This value is set as the
OLLAMA_HOSTenvironment variable in Ollama. The default base URL ishttp://127.0.0.1:11434.To refresh the server's list of models, click .
In the Ollama Model field, select an embeddings model. This example uses
all-minilm:latest.Connect the Ollama embeddings component to a flow. For example, this flow connects a local Ollama server running a
all-minilm:latestembeddings model to a Chroma DB vector store to generate embeddings for split text.
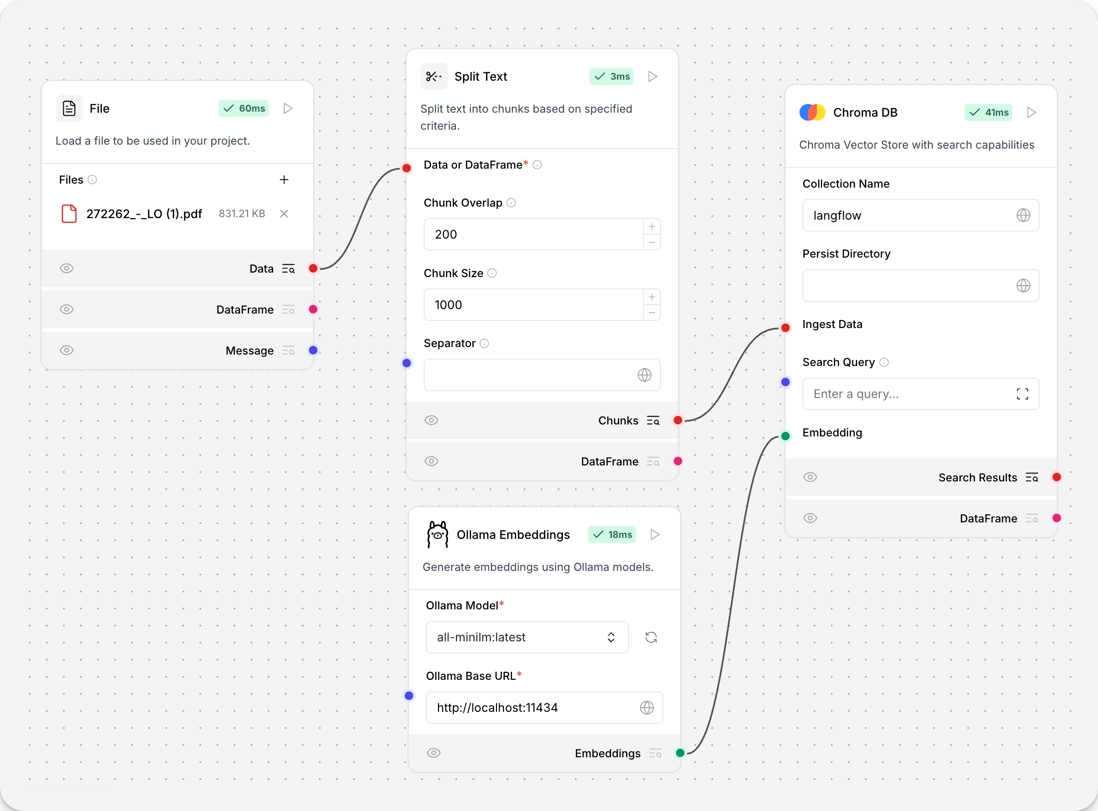
For more information, see the Ollama documentation.
Inputs
Ollama Model
String
Name of the Ollama model to use (default: llama2)
Ollama Base URL
String
Base URL of the Ollama API (default: http://localhost:11434)
Model Temperature
Float
Temperature parameter for the model. Adjusts the randomness in the generated embeddings
Outputs
embeddings
Embeddings
An instance for generating embeddings using Ollama
OpenAI Embeddings
This component is used to load embedding models from OpenAI.
Inputs
OpenAI API Key
String
The API key to use for accessing the OpenAI API
Default Headers
Dict
Default headers for the HTTP requests
Default Query
NestedDict
Default query parameters for the HTTP requests
Allowed Special
List
Special tokens allowed for processing (default: [])
Disallowed Special
List
Special tokens disallowed for processing (default: ["all"])
Chunk Size
Integer
Chunk size for processing (default: 1000)
Client
Any
HTTP client for making requests
Deployment
String
Deployment name for the model (default: text-embedding-3-small)
Embedding Context Length
Integer
Length of embedding context (default: 8191)
Max Retries
Integer
Maximum number of retries for failed requests (default: 6)
Model
String
Name of the model to use (default: text-embedding-3-small)
Model Kwargs
NestedDict
Additional keyword arguments for the model
OpenAI API Base
String
Base URL of the OpenAI API
OpenAI API Type
String
Type of the OpenAI API
OpenAI API Version
String
Version of the OpenAI API
OpenAI Organization
String
Organization associated with the API key
OpenAI Proxy
String
Proxy server for the requests
Request Timeout
Float
Timeout for the HTTP requests
Show Progress Bar
Boolean
Whether to show a progress bar for processing (default: False)
Skip Empty
Boolean
Whether to skip empty inputs (default: False)
TikToken Enable
Boolean
Whether to enable TikToken (default: True)
TikToken Model Name
String
Name of the TikToken model
Outputs
embeddings
Embeddings
An instance for generating embeddings using OpenAI
Text embedder
This component generates embeddings for a given message using a specified embedding model.
Inputs
embedding_model
Embedding Model
The embedding model to use for generating embeddings.
message
Message
The message for which to generate embeddings.
Outputs
embeddings
Embedding Data
Data object containing the original text and its embedding vector.
VertexAI Embeddings
This component is a wrapper around Google Vertex AI Embeddings API.
Inputs
credentials
Credentials
The default custom credentials to use
location
String
The default location to use when making API calls (default: us-central1)
max_output_tokens
Integer
Token limit determines the maximum amount of text output from one prompt (default: 128)
model_name
String
The name of the Vertex AI large language model (default: text-bison)
project
String
The default GCP project to use when making Vertex API calls
request_parallelism
Integer
The amount of parallelism allowed for requests issued to VertexAI models (default: 5)
temperature
Float
Tunes the degree of randomness in text generations. Should be a non-negative value (default: 0)
top_k
Integer
How the model selects tokens for output, the next token is selected from the top k tokens (default: 40)
top_p
Float
Tokens are selected from the most probable to least until the sum of their probabilities exceeds the top p value (default: 0.95)
tuned_model_name
String
The name of a tuned model. If provided, model_name is ignored
verbose
Boolean
This parameter controls the level of detail in the output. When set to True, it prints internal states of the chain to help debug (default: False)
Outputs
embeddings
Embeddings
An instance for generating embeddings using VertexAI
Last updated